

Working with yield in C#



TLDR: Explore C#’s yield keyword for efficient code. Understand its history, usage, and memory benefits, making code cleaner and reducing memory usage.
Programming in C# offers many features. One of them, introduced in C# version 2.0, is a powerful feature called yield. Despite its complexity, understanding yield correctly can greatly benefit your projects.
In this blog, we’ll delve into the yield keyword and its usage in C#, focusing specifically on memory efficiency. We’ll explore how yield can help you reduce memory consumption while handling large data sets.
Understanding the history
Yield was introduced in C# 2.0. Before its introduction, iterating over a collection required implementing a custom iterator using the IEnumerator interface. This involved creating a class that implemented IEnumerator and IEnumerable interfaces and managing the iterator’s state manually.
What is the yield keyword?
The yield keyword is used for stateful iteration over a collection in a customized manner. The yield keyword informs the compiler that the method that contains it is an iterator block.
In other words, yield will provide the next element or value from the sequence when iterating a sequence. We don’t need to wait to complete the iteration to get the items from the iterating sequence. It will return one element in the collection at a time. Simply, when using the yield return statement, we don’t need to create a temporary collection (array, list, etc.) to store the data and eventually return all the data together.
Two main concepts of yield in C#
The [yield](learn.microsoft.com/en-us/dotnet/csharp/lan.. "yield statement in C# documentation") statement has the two following forms:
yield return: This statement returns one element at a time and requires IEnumerable or IEnumerator as the return type.
yield break: This statement ends the iterator block.
Let’s understand these concepts with some examples.
yield example with C#
First, let’s discuss the example using the classic approach in C#.
var numList = new List() { 1, 4, 5, 7, 4, 10 };
var sumResults = SumOfNums(numList);
foreach (var sumResult in sumResults) { Console.WriteLine(sumResult); }
IEnumerable SumOfNums(List nums) { var results = new List(); var sum = 0; foreach (var num in nums) { sum += num; results.Add(sum); }
return results; }
In this example, we calculated the sum of the values in the numList list using the SumOfNums method. Inside the SumOfNums method, we created a list to return the results list.
After running the previous code examples, we’ll get the following output.
Output : 1 5 10 17 21 31
If we have thousands of elements in the array, we must wait until it returns the results list using this approach. It would slow the computation and require a significant amount of memory to execute.
Now, let’s understand how this classic approach works using a simplified flow for the previous example.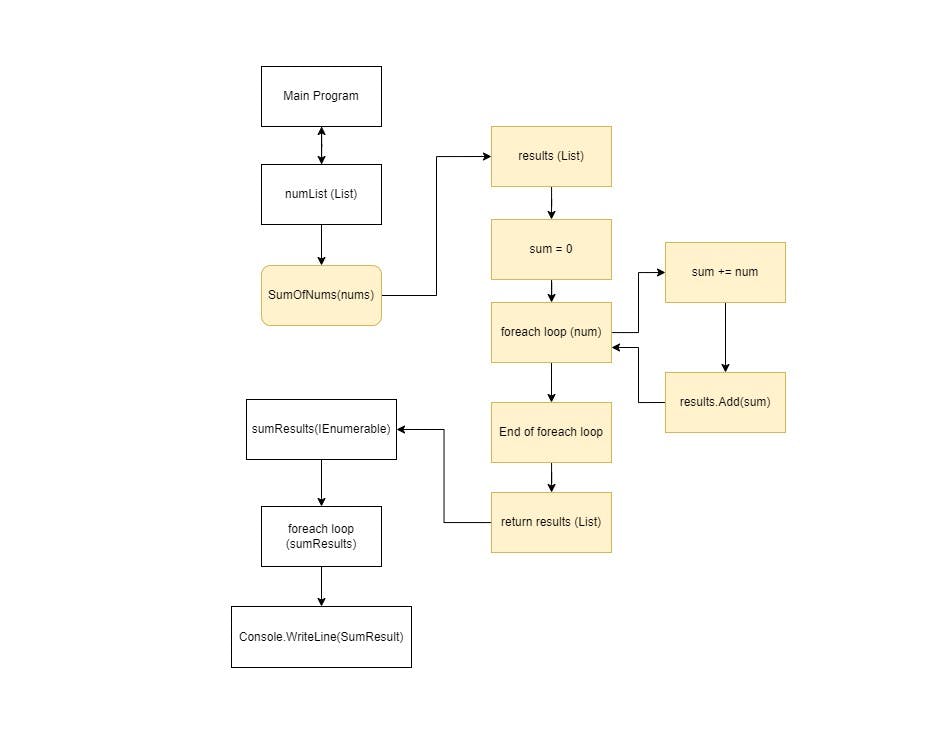
In this flow chart:
- Main Program: This marks the program’s beginning, serving as the entry point of our code.
- Initialization: Within the Main Program, we initialize a variable called numList, comprising a series of integers.
- Method call: The program calls the SumOfNums method, passing numList as an argument. This method call is depicted as an arrow leading to the SumOfNums blocks.
- SumOfNums method: Inside the SumOfNums method, several components come into play:
- Initialization: This step involves creating a results list to store intermediate results.
- Sum initialization: A sum variable is initialized to 0 to accumulate the sum of the numbers.
- Foreach loop (num): A foreach loop iterates through each element (num) in the nums list.
- Sum update: Inside the loop, the sum variable is updated by adding the current num to it, calculating the cumulative sum of the numbers.
- Results update: The sum value is added to the results list, storing each intermediate result.
- End of Foreach loop: After processing all elements in the nums list, the loop ends.
- Return results: The results list, now containing all the intermediate sums, is returned from the SumOfNums method.
- Main Program (continued): The returned results list is stored in the sumResults variable in the Main Program.
- Foreach loop (sumResult): The program enters another foreach loop, iterating through the elements of sumResults, which is of type IEnumerable.
- Printing: Inside this foreach loop, each sumResult value is printed using WriteLine(sumResult).
Refer to the following code example to understand how using the yield keyword improves this approach.
var numList = new List() { 1, 4, 5, 7, 4, 10 };
foreach (var result in SumOfNums(numList)) { Console.WriteLine(result); }
IEnumerable SumOfNums(List nums) { var sum = 0; foreach (var num in nums) { sum += num; yield return sum; } }
We have used the yield keyword, so we don’t need to wait until the SumOfNums method is completed to print the results like in the previous example.
When the SumOfNums method is called, it executes until it reaches the yield return statement. At that point, the control shifts to the preceding foreach loop, which runs the SumOfNums method. Then, it will print the result and proceed to the next iteration of the SumOfNums method. This process continues until the iteration of the entire list is completed.
Following is the output of the example. There isn’t any change in the output.
Output : 1 5 10 17 21 31
For the previous example, let’s understand how this yield approach functions through a simplified flow.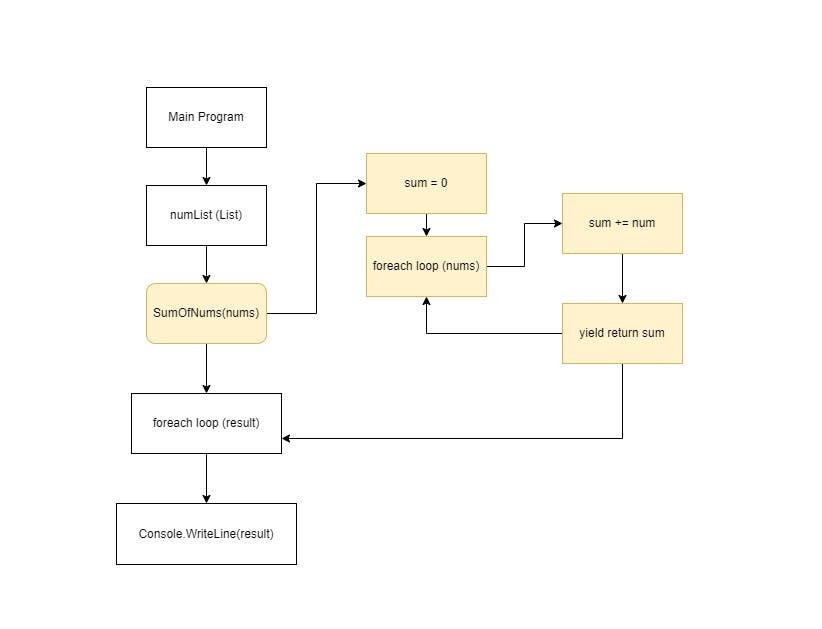
In this flow chart:
- Main Program: The program initiates in the Main Program section, serving as the code’s entry point.
- Initialization: Within the Main Program, we initialize a numList variable, representing a list containing a series of integers: [1, 4, 5, 7, 4, 10].
- Method call: Next, the program calls the SumOfNums(numList) method, passing numList as an argument. This method call is depicted as an arrow leading to the SumOfNums() block.
- SumOfNums method: Within the SumOfNums() method, several components come into play:
- Initialization: We initialize a sum variable to 0.
- Foreach loop: A foreach loop iterates through each element of the numList passed as an argument.
- Accumulation: Inside the loop, we update the sum variable by adding the current element from numList to it.
- Yield return: After updating the sum, we encounter a yield return statement, which yields the current value of the sum to the calling code. This characteristic of the yield keyword facilitates the generation and return of values one at a time, conserving memory.
- Main Program (continued): The control returns to the Main Program after each yield return statement. In this section, we have a foreach loop that iterates over the values returned by the SumOfNums() method.
- Printing: Inside the foreach loop, each value (represented by a result) is printed using Console.WriteLine(result).
Understanding the memory usage of each approach
Let’s understand how memory usage works with each approach.
Memory usage using the classic approach
First, consider an example of handling a huge array of elements using the classic approach.
Refer to the following code example.
var arr = new int[1000];
Stopwatch stopwatch = new Stopwatch(); stopwatch.Start(); var result = SumOfNums(arr.ToList()); stopwatch.Stop(); Console.WriteLine("Time elapsed using classic approach: " + stopwatch.ElapsedMilliseconds + "ms");
long memoryBefore = GC.GetTotalMemory(true); result = SumOfNums(arr.ToList()); long memoryAfter = GC.GetTotalMemory(true); Console.WriteLine("Memory used using classic approach: " + (memoryAfter - memoryBefore) + "bytes");
In the previous example, we executed the SumOfNums method for the classic approach and then measured the time and memory consumption for it. Refer to the following output.
Time elapsed using classic approach: 0ms Memory used using classic approach: 8508bytes
Memory usage using the yield approach
Let’s also consider an example with a large array of elements using the yield approach to measure the time and memory consumption.
var arr = new int[1000];
Stopwatch stopwatch = new Stopwatch(); stopwatch.Start(); var result = SumOfNums(arr.ToList()); stopwatch.Stop(); Console.WriteLine("Time elapsed using yield approach: " + stopwatch.ElapsedMilliseconds + "ms");
long memoryBefore = GC.GetTotalMemory(true); result = SumOfNums(arr.ToList()); long memoryAfter = GC.GetTotalMemory(true); Console.WriteLine("Memory used using yield approach: " + (memoryAfter - memoryBefore) + "bytes");
In this example, we’ve executed the SumOfNums method in the yield approach and then measured the time and memory consumption using this approach to compare it with the classic approach.
Refer to the following output for the measured results of time and memory consumption using the yield approach.
Time elapsed using yield approach: 0ms Memory used using yield approach: 4112bytes
As you can see, the yield approach is much more memory-efficient, consuming only 4,112 bytes of memory compared to the classic approach’s 8,508 bytes. This memory optimization becomes increasingly crucial when handling large data sets or sequences. While the elapsed time may be similar in both approaches, the memory savings provided by the yield approach can enhance the overall app performance.
yield break
The yield break statement serves to terminate the iterator (array, list, etc.) of the block. Let’s explore the function of the yield break statement with an illustrative example.
var numList = new List() { 1, 4, 5, 7, 4, 10 };
foreach (var result in SumOfNums(numList)) { Console.WriteLine(result); }
IEnumerable SumOfNums(List nums) { var sum = 0; for (int i = 0; i < nums.Count; i++) { if (i == 2) { yield break; } sum += nums[i]; yield return sum; } }
In the code example, an if condition statement is used to check whether the value of i is equal to 2. Upon satisfying this condition, the yield break statement is executed, effectively halting the iteration of the block. Consequently, no further items are returned. This usage of the yield break statement enables the termination of the iterator within the block.
After executing the previous code examples, we’ll get the following output:
Output : 1 5
From this output, we observe that only two results are printed. This outcome arises from the termination of the for loop when the value of i equals 2, thereby concluding the iteration.
The usage of yield with memory usage
The yield keyword is a powerful tool for memory-efficient programming, especially in scenarios involving large data sets or sequences.
Let’s delve deeper into how yield influences memory usage:
- Lazy evaluation: Yield enables lazy evaluation, allowing elements to be generated and returned one at a time as needed. This approach contrasts with generating and storing all elements in memory simultaneously. It avoids the necessity for a substantial up-front memory allocation.
- No intermediate collection: In the absence of yield, the creation of intermediate collections (e.g., lists) to store results before their return becomes necessary. These collections consume memory. Conversely, yield eliminates the need for such collections, resulting in significant memory savings.
- Iterative consumption: With yield, the memory footprint remains relatively constant, regardless of the data set’s size. We only need memory to store the current state of the iteration, not the entire data set.
Reduced garbage collection: When we create intermediate collections, they become objects that need to be managed by the garbage collector. Excessive memory usage can trigger more frequent garbage collections, impacting performance. The yield reduces the number of objects to be collected, leading to more efficient memory management. - Streaming: The yield facilitates data processing in a streaming fashion, particularly advantageous when dealing with external data sources or data sets that exceed memory capacity. It enables immediate processing of available data without necessitating the entire data set’s loading into memory.
- Reduced memory pressure: In scenarios featuring limited available memory, the utilization of yield aids in alleviating memory pressure. By retaining only a minimal amount of data in memory at any given time, programs become more memory-efficient.
Requirements for using yield
Certain prerequisites must be met to utilize the yield keyword effectively:
- Avoid using yield within an unsafe block.
- Avoid using ref or out keywords with method parameters and properties.
- The use of a yield return statement within a try-catch block is prohibited. However, it is permissible within a try statement situated inside the try-finally block.
- Yield break statements may be utilized within try-catch and try-finally blocks.
Conclusion
Thanks for reading! This article has discussed the yield keyword in C# with a few examples. We have also listed a few requirements that should be met to use the yield keyword. The point to highlight is that when we use the yield keyword with a huge iteration process, it will require less memory than usual. Furthermore, it will help to reduce the lines of code and maintain the code cleanly.
I hope this article helped you learn about the yield keyword in C#. Feel free to share your opinions or experiences in the comment section below. For questions, you can contact us through our [support forum](syncfusion.com/forums "Syncfusion Support Forum"), [support portal](support.syncfusion.com "Syncfusion Support Portal"), or [feedback portal](syncfusion.com/feedback "Syncfusion Feedback Portal"). We are happy to assist you!
Related blogs
- [Converting XLS to XLSX Format in Just 3 Steps Using C#](syncfusion.com/blogs/post/convert-xls-to-xl.. "Blog: Converting XLS to XLSX Format in Just 3 Steps Using C#")
- [Print Excel Documents in Just 4 Steps Using C#](syncfusion.com/blogs/post/print-excel-in-cs.. "Blog: Print Excel Documents in Just 4 Steps Using C#")
- [3 Simple Steps to Split an Excel File into Multiple Excel Files in C#](syncfusion.com/blogs/post/split-excel-file-.. "Blog: 3 Simple Steps to Split an Excel File into Multiple Excel Files in C#")
- [Merge Multiple Excel Files into One in Just 3 Steps Using C#](syncfusion.com/blogs/post/merge-multiple-ex.. "Blog: Merge Multiple Excel Files into One in Just 3 Steps Using C#")